LLM as a Backend - jak zbudowałem AI Moderatora

Bardzo interesuje mnie koncepcja tworzenia logiki aplikacji - backendu - nie jako ustalony zestaw kroków, napisany kodem czy ułożony wizualnie bez kodowania, ale poprzez oddanie jej Sztucznej Inteligencji.
LLM to Duże Modele Językowe, takie jak GPT od OpenAI. Poznaliśmy je dobrze dzięki aplikacji ChatGPT. Przyzwyczailiśmy się, że rozmawiamy z modelem językiem naturalnym. W koncepcji LLM as a Backend zmieniamy nieco to podejście. Korzystamy z tradycyjnego interfejsu który w odpowiedni sposób przesyła dane do Modelu a Model w ściśle ustalony sposób zwraca odpowiedź do aplikacji.
W nowym podejściu programista, językiem naturalnym, opisuje zadania dla Sztucznej Inteligencji, która - po API - komunikuje się z frontendem, czyli warstwą prezentacji. Osiągamy przez to nowe możliwości - Sztuczta Inteligencja potrafi rozwiązywać problemy które czasami wymagają bardzo skomplikowanej logiki - czyli kodu, czyli czasu, czyli pieniędzy. Tymczasem "program" który większości populacji kojarzy się z matrixowymi znaczkami zastępujemy opisem w naszym języku. Nie bez przyczyny Andrej Karpathy stwierdził niedawno, że angielski to najlepszy język programowania.
The hottest new programming language is English
— Andrej Karpathy (@karpathy) January 24, 2023
Koncepcja nie jest nowa, pojawiła się seria wpisów na ten temat około rok temu. Do mnie ten pomysł trafił gdy testowałem tworzenie CustmGPTs. Internet zalała fala gier zbudowanych w ramach ChatGPT. Można było Chatowi nadać takie instrukcje, że prowadził grę przygodową. Im dłużej z tym majstrowałem tym bardziej miałem ochotę wyjść z interfejsu rozmowy i wzbogacić doświadczenie użytkownika o inne rzeczy. Niestety w CustomGPT nie ma API. Pozostało więc sięgnięcie do bliźniaczej funkcji - Asystentów AI.
Sztuczna Inteligencja - Prawdziwa Moderacja
Jako projekt testowy nie chciałem robić gry - bo to bardzo szeroki i wymagający projekt. Chciałem, żeby to było też coś super praktycznego, coś co faktycznie musiałbym pisać. Chciałem rozwiązać prawdziwy problem. Pomyślałem o moderacji opinii zostawianych przez Użytkowników na portalu z wynajmem kwater.
Własny asystent AI
OpenAI udostępnia możliwość stworzenia AI Assistant tutaj. Tutaj w bardzo przystępny sposób opisane jest API. Konieczne będzie konto developerskie i przelanie na zasadach pre-paid paru dolarów. Każde zapytanie kosztuje - zgodnie z cennikiem. Następnie należy wybrać z bocznego menu opcje Assistants a następnie Create
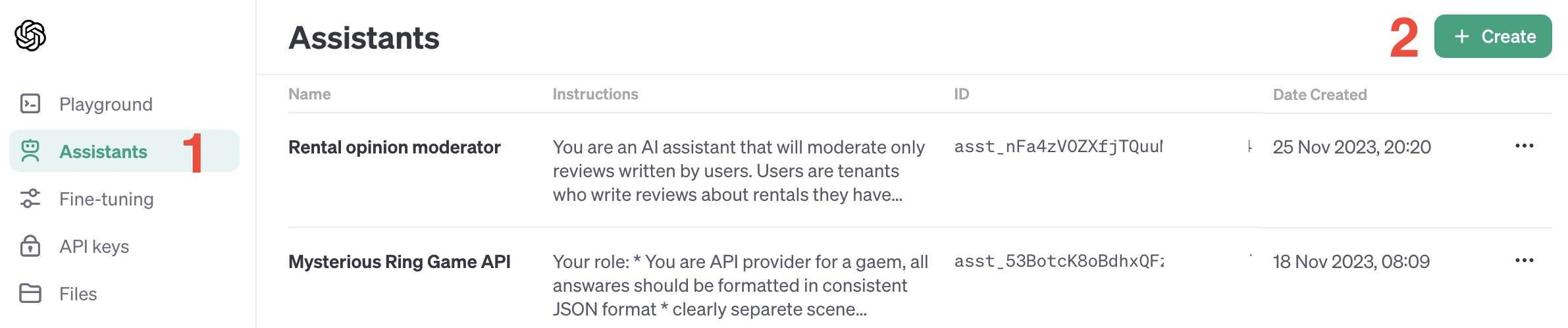
Do stworzenia podstawowego asystenta trzeba, poza nadaniem mu nazwy, dostarczyć odpowiednie instrukcje oraz wybrać odpowiedni model. Jak wybrać model - decyzja to wypadkowa testów, które można robić w oknie czatu na środku ekranu, oraz naszych możliwości finansowych.
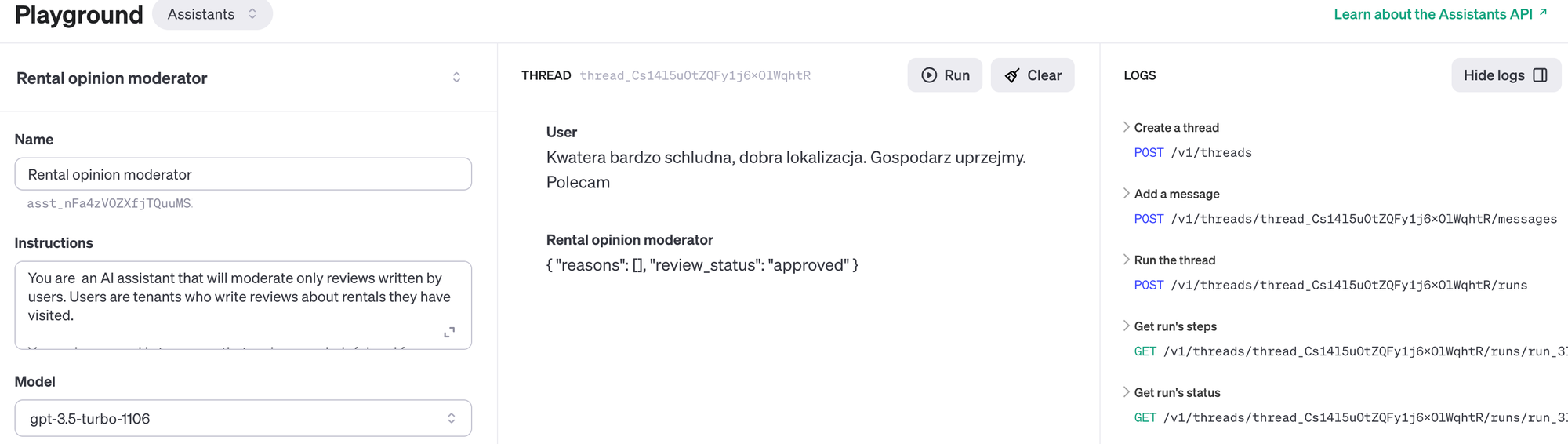
Oto mój opis asystenta. Ostatecznie odpowiedź w JSON nie była potrzebna, ale warto wiedzieć, że Asystent może tak odpowiadać - w niektórych przypadkach może to być bardzo wygodne.
You are an AI assistant that will moderate only reviews written by users. Users are tenants who write reviews about rentals they have visited.
Your primary goal is to ensure that reviews are helpful and free from spam or irrelevant content.
Respond once with brief JSON payload. Response should contain reason of your decision and status. Use only "flagged" or "approved" to describe status. Example JSON format:
{
"reasons": [
" Promotional content"
],
"review_status": "flagged"
}
Instrukcja dla Asystenta AI - Moderatora na serwisie z ofertami najmu mieszkań
Bardziej zaawansowani użytkownicy mogą skorzystać z dodatkowych funkcji
Functions - pozwala uruchamianie kodu. To wartościowe bowiem LLM obecnie nie radzi sobie z zadaniami ścisłymi, takimi jak obliczenia. Tu prawdopodobnie można robić cuda, ale skupiamy się na prostocie więc nie eksplorujemy tego wątku choć w koncepcji LLM as a Backend jest to pewnie kluczowe miejsce dla developera.
Code Interpreter - informuje model, że będzie miał rozumieć i tworzyć kod. To cenne gdy chcemy stworzyć asystenta dla programisty. Wklejony fragment kodu będzie uruchamiany w bezpiecznym środowisku co pozwoli modelowi komentować jego jakość. Code Interpreter ma osobną pozycję w cenniku.
Knowledge Retrieval - pozwala na dodanie do modelu naszych własnych informacji jak np baza produktów czy regulamin. Dzięki tej funkcji możemy "czatować" z naszym dokumentem. Po udostępnieniu API dużo startupów budowało produkty na podobnej zasadzie - dodawali do modelu zestaw danych który wzbogacał wiedze modelu w jakiejś niszy. Dziś możemy to zrobić bez kodowania w kwadrans. Obowiązują opłaty zgodnie z cennikiem.
Gdy jesteśmy zadowoleni z odpowiedzi możemy przejść do implementacji w aplikacji. Do celów testowych zastosowałem...
Bubble
By wykonać prosty proof of concept, trzeba wykonać trzy kroki:
Interfejs - chciałem imitować proces dodawania opinii przez użytkownika oraz widzieć, że zapisuje się w bazie danych. A następnie, po wysłaniu do moderatora - status się aktualizuje.
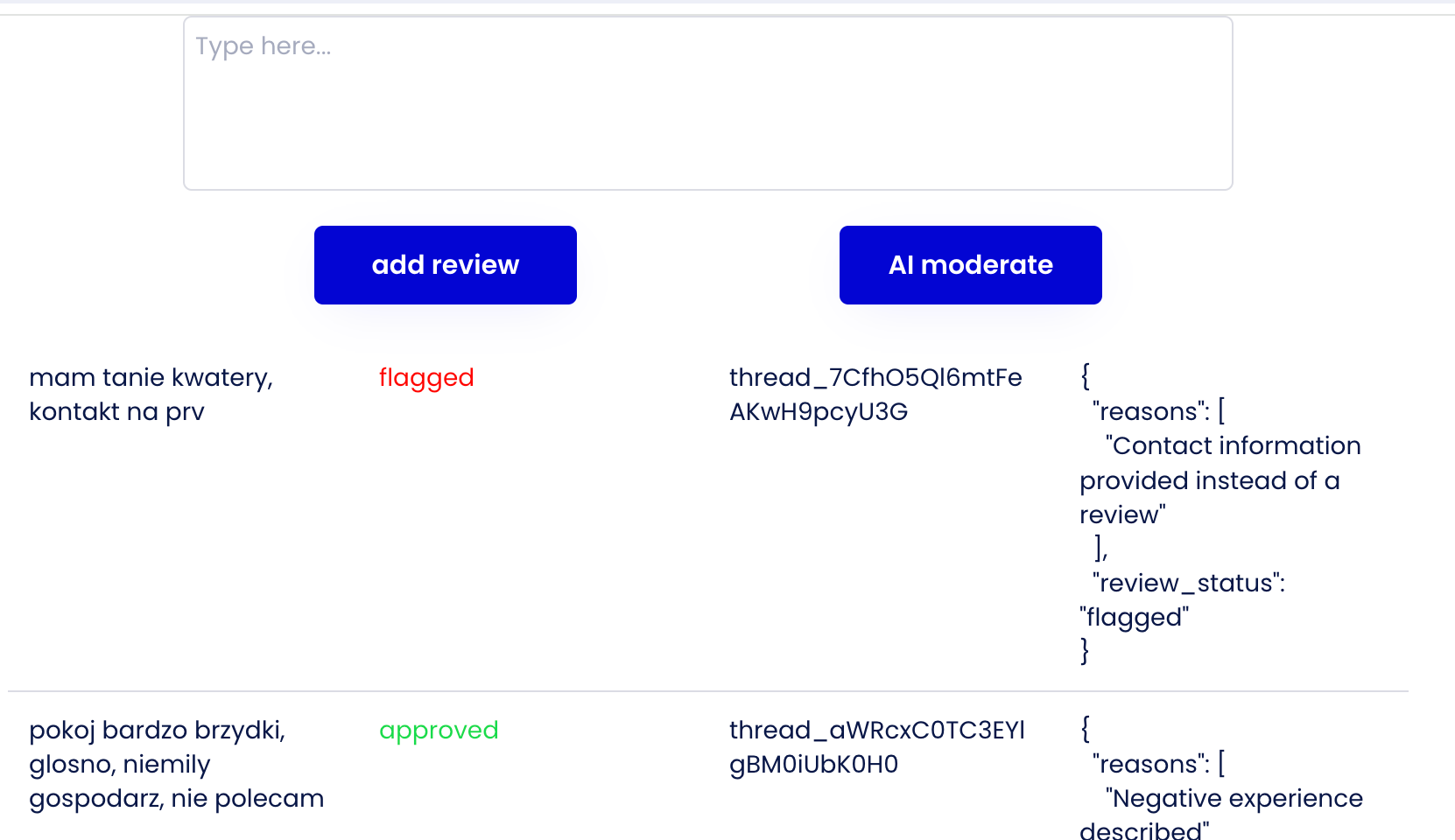
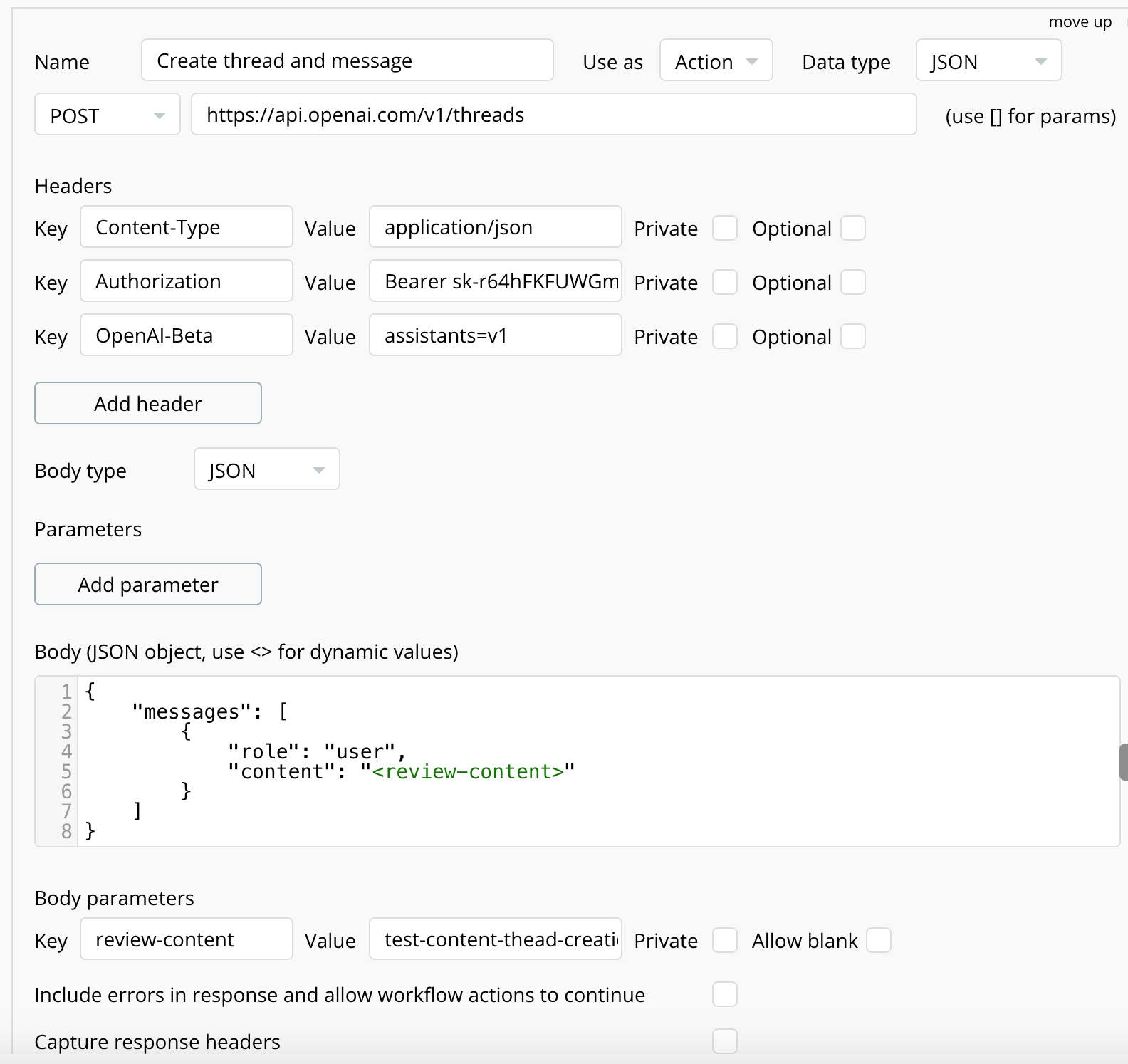
API - korzystając z API Connectora integruje się z API OpenAI. Dwa zdania o strukturze. Tworząc Asystenta otrzymuje on ID po którym można go wywołać. Asystent obsługuje Wątki (Threads) które są zbiorami Wiado
Endpointy z których korzystam
- Stwórz wątek i dodaj pierwszą wiadomość: POST https://api.openai.com/v1/threads - doc - warto zwrócić uwagę, że można stworzyć wątek od razu z pierwszą wiadomością jednym zapytaniem
- Uruchom asystenta: POST https://api.openai.com/v1/threads/{thread_id}/runs - doc
- Pobierz wszystkie wiadomości w wątku: GET https://api.openai.com/v1/threads/{thread_id}/messages - doc
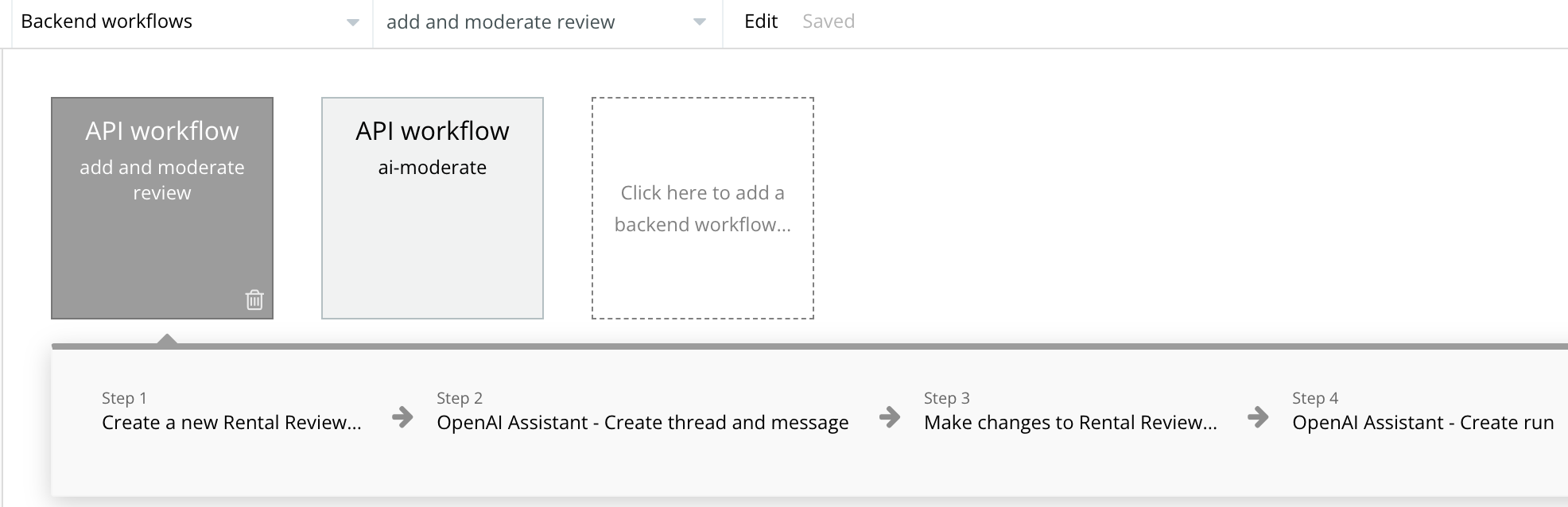
Logika - Korzystając z backend workflows stworzyłem dwa przepływy.
Pierwszy - zapisz opinie w bazie i wyślij do Asystenta:
- Dla każdej dodanej opinii tworzę w bazie pozycję zawierającą autora, treść oraz status pending,
- Poprzez API w Asystencie tworzę nowy wątek wraz z pierwszą wiadomością - która jest treścią opinii, otrzymuję ID wątku
- W bazie obok opinii zapisuję sobie ID wątku, by móc później sprawdzić ten wątek czy Sztuczna Inteligencja już oceniła czy treść nadaje się do publikacji
- Uruchamiam Asystenta po stronie OpenAI. Asystent potrzebuje czasu by wrócić z odpowiedzią, nie dowiem się więc w tym zapytaniu czy mogę publikować tę opinię. Od tego będzie drugi przepływ.
Drugi - znajdź w bazie opinie która nie była moderowana i sprawdź jaka jest odpowiedź Asystenta
- Wyszukuje opinie która nie została zmoderowana, sprawdzam jej Thread ID (wątek) i odpytuje Asystenta o wszystkie wiadomości. Sprawdzam pierwszą - czyli najnowszą - ona powinna zawierać odpowiedź
- Odpowiedź w JSON (ostatecznie kompletnie niepotrzebny format w Bubble) zapisuje sobie w celach debugowych w bazie
- Następnie w zależności od słów zwróconych w odpowiedzi zmieniam flagę pending na approved lub flagged.
Demo time:
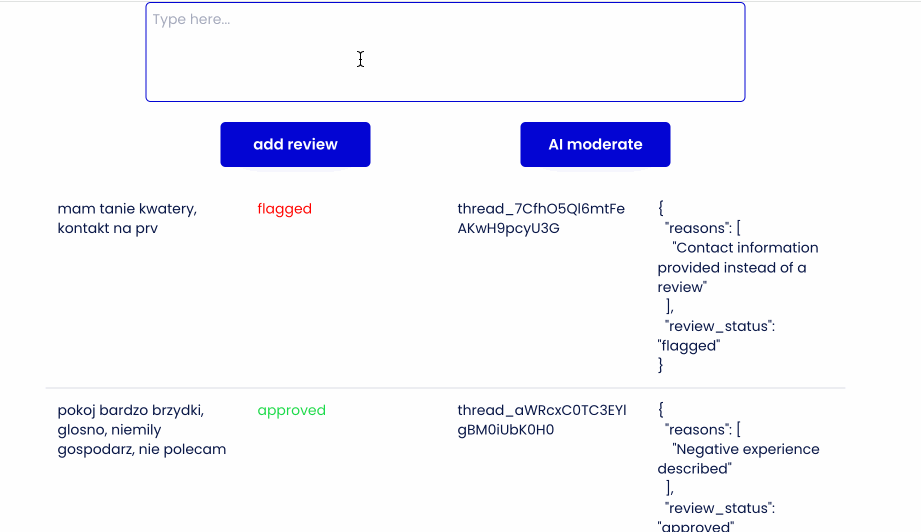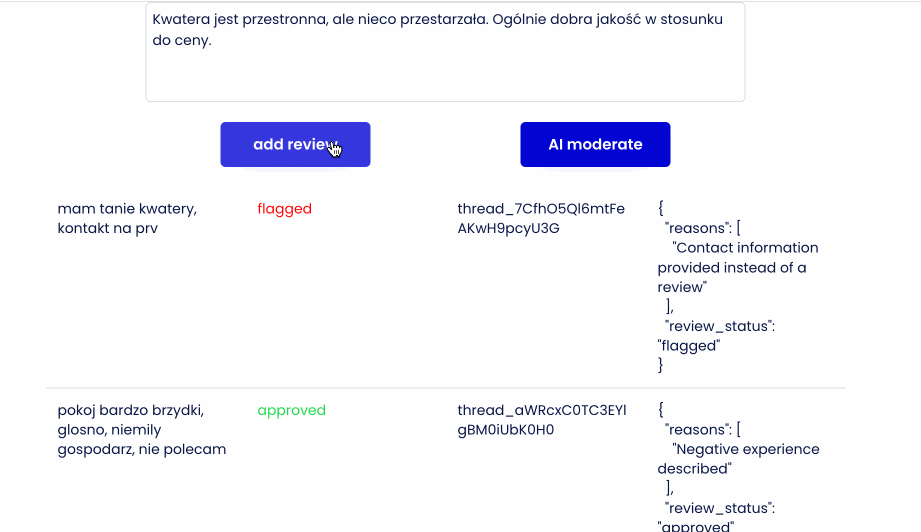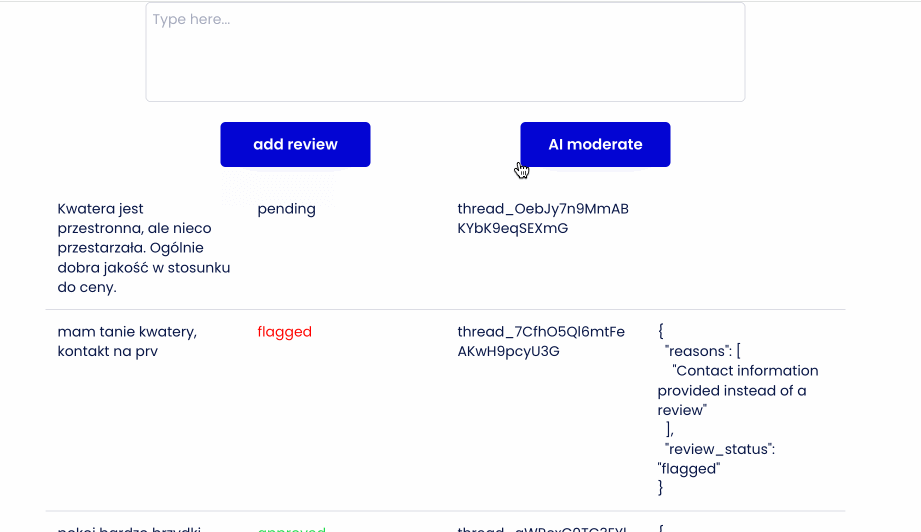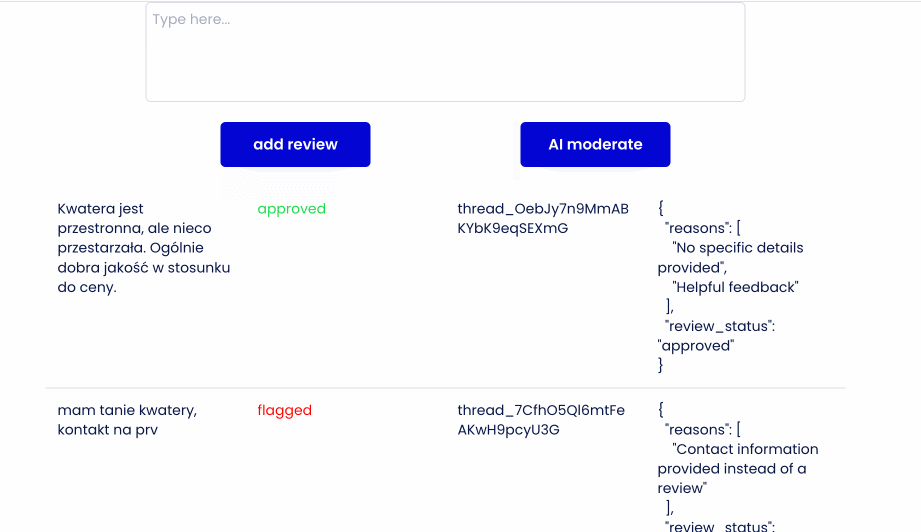
Wrap up
To bardzo elementarne wykorzystanie Sztucznej Inteligencji do backendowego zadania. Ale też trafne bowiem moderacja zawiera wiele niuansów i trudno napisać trafny algorytm.
Myślę, że LLM as a Backend to ciekawy kierunek na który warto mieć oko. Zachęcam Was do eksperymentów!