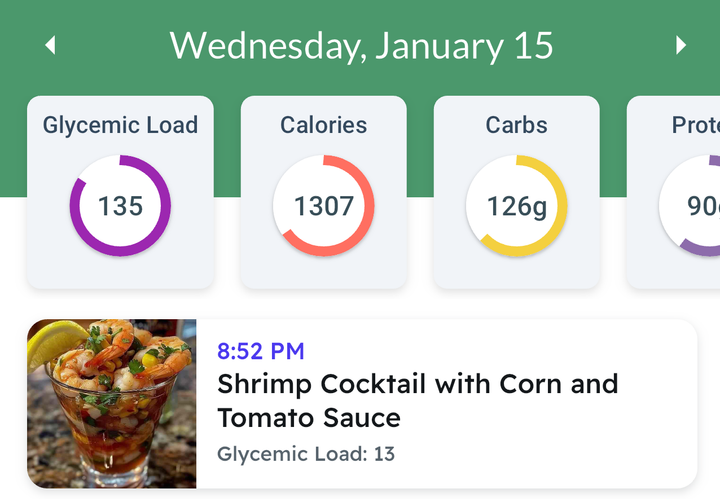
Gdy AI uczy się na swoich kreacjach - umiera

Dziś o Model Collapse - czyli Załamanie Modelu, zjawisku opisanym w badaniu The Curse of Recursion: Training on Generated Data Makes Models Forget czyli w wolnym tłumaczeniu Klątwa Rekurencji: Szkolenie na Generowanych Danych Powoduje Zapominanie przez Modele. Tytuł jest nieco click-baitowy, więc uściślę, że problem ten opisany jest na przykładzie Generative AI, głównie Large Language Models a każdego modelu AI.

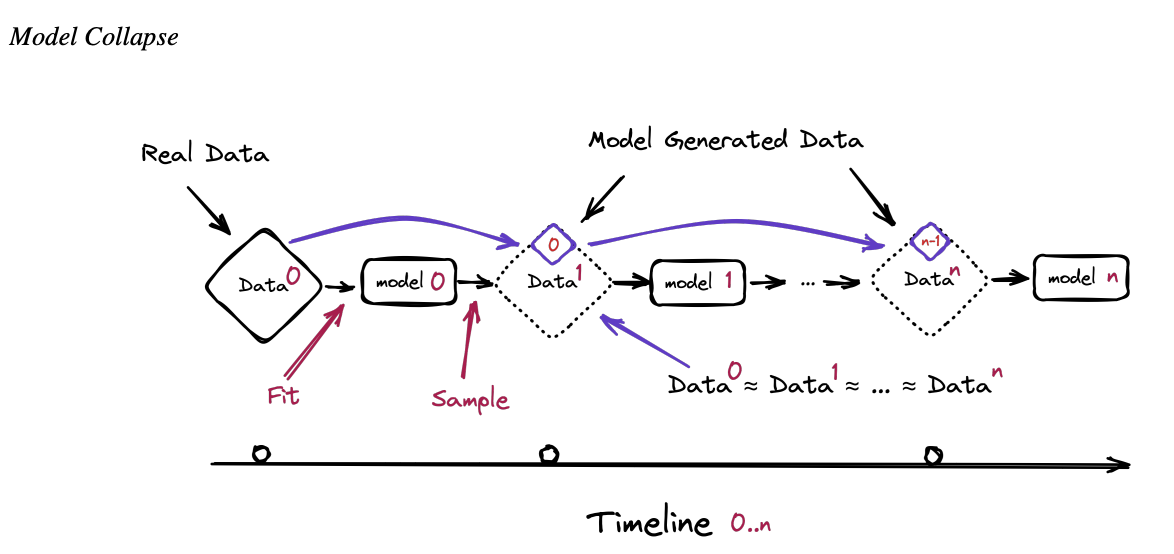
Załamanie Modelu
Załamanie Modelu to proces degeneracji, który dotyka kolejne pokolenia nauczonych modeli generatywnych. W tym procesie dane stworzone przez modele zanieczyszczają zestaw treningowy następnych generacji, co prowadzi do błędnego postrzegania przez nie rzeczywistości. Możemy wyróżnić dwa szczególne przypadki: wczesne i późne załamanie modelu. W wczesnym załamaniu model zaczyna tracić informacje o skrajnych wartościach dystrybucji, natomiast w późnym załamaniu model miesza różne typy oryginalnych dystrybucji i zbiega się do dystrybucji, która ma niewiele wspólnego z oryginalną, często charakteryzującej się bardzo małą zmiennością.

Opisywany problem nie jest tożsamy z procesem catastrophic forgetting (katastrofalne zapominanie?) w którym raz nauczony czegoś model nagle zapomina tego.
Jak to się dzieje?
To skomplikowane. Postaram się to uprościć, ale po pełne wytłumaczenie odsyłam do samego badania. Są dwa główne powody
Błąd statystycznej aproksymacji - pośrednio teraz to robie tworząc uproszczone wyjaśnienie - tekst ten traci dużą część ładunku informacyjnego. Dla eksperta w obszarze statystyki czy uczenia maszynowego będzie to zbyt ogólne wyjaśnienie. W kontekście modeli musimy przykład umieścić w statystyce - badając preferencje kulinarne europejczyków po przepytaniu polaków może nam wyjść, że schabowy to najpopularniejsze danie. Tracimy wiedze o różnorodności kuchni przez małą próbkę danych.
Jest jeszcze Błąd funkcjonalnej aproksymacji ale przyznam szczerze - nie rozumiem go. Dlatego poprosiłem GPT-4 o przykład wyjaśniający. Oto on:
Wyobraź sobie, że masz do wykonania zadanie, które wymaga użycia dwóch różnych narzędzi - na przykład śrubokręta płaskiego i krzyżakowego. Jednak masz dostęp tylko do jednego z nich, powiedzmy śrubokręta płaskiego. Próbujesz użyć go do wszystkich śrub, zarówno płaskich, jak i krzyżakowych. W przypadku śrub płaskich śrubokręt działa idealnie, ale kiedy próbujesz nim odkręcić śrubę krzyżakową, nie jest to skuteczne i sprawia trudności.
W tym przykładzie śrubokręt płaski jest naszym "aproksymatorem funkcjonalnym", a różne rodzaje śrub to różne dane, z którymi mamy do czynienia. Użycie śrubokręta płaskiego do śrub płaskich jest jak wykorzystanie właściwego modelu do danych, dla których został on zaprojektowany. Natomiast próba używania go do śrub krzyżakowych to jak próba zastosowania modelu do danych, dla których nie jest on odpowiedni. W tym przypadku model (śrubokręt płaski) nie jest wystarczająco "ekspresywny" lub odpowiedni, aby skutecznie poradzić sobie z zadaniami (śrubami krzyżakowymi), dla których nie został zaprojektowany.
W kontekście modeli sztucznej inteligencji, błąd funkcjonalnej aproksymacji występuje, gdy model nie jest w stanie odpowiednio przetworzyć lub zrozumieć danych, ponieważ jego struktura lub sposób uczenia nie są dostosowane do specyfiki tych danych. To prowadzi do błędów w przewidywaniach lub analizach modelu.
Jak tego uniknąć?
Niestety na dziś nie ma błyskotliwego sposobu na uniknięcie tego problemu. Należy zadbać o jakość danych, o fakt by w każdej następnej iteracji nie było nadreprezentacji danych wygenerowanych przez AI. Co jest praktycznie niewykonalne. Rok temu, wraz z premierą ChatGPT, rozpoczęła się rewolucja AI. Każdy produkt stara się zintegrować w jakimś zakresie generatywną sztuczną inteligencję - nie wiemy ile czytanego przez nas tekstu jest stworzona przez ludzi a ile przez modele.
Psujące się dane i premia pierwszeństwa
Nieprzewidzianą konsekwencją powyższego jest, znana w biznesie, premia za pierwszeństwo. Oznacza, że wprowadzający nowy produkt czy usługę ma swoistą przewagę nad konkurencją. Zazwyczaj wynika ona z tego, że przez czas w którym konkurencja przychodzi z odpowiedzią, Wprowadzający innowację może budować u Klienta świadomość marki rozwiązania oraz dokonywać dalszych iteracji.
Jeśli teza badania się potwierdzi, firmy które jako pierwsze zabezpieczyły zestawy danych sprzed tsunami treści generowanych przez Sztuczną Inteligencję będą miały dodatkową przewagę. Podmiot który dołączy później i będzie szukał w internecie danych nie ustali które są ludzkie a które wygenerowane. Dane zostały już zanieczyszczone.